Sometimes the best explanations of things come when we are trying to explain them to outsiders, people not expected to understand our particular forest of acronyms, slangs and conventions which, while allowing speedier communication, can also channel thinking down the same tired old tracks time after time. Such an example I think is the UK Government Actuary’s Department (GAD) paper on Pensions for Public Service Employees in the UK, presented to the International Congress of Actuaries last month in Washington.
Not a lay audience admittedly, but one sufficiently removed from the UK for the paper’s writers to need to represent the bewildering complexity of UK public sector pension provision very clearly and concisely. The result is the best summary of the current position and the planned reforms that I have seen so far, and I would strongly recommend it to anyone interested in public sector pensions.
There are two points which struck me particularly about the summary of the reforms, designed to bring expenditure on public service pensions down from 2.1% of GDP in 2011-12 to 1.3% by 2061-62.
The first came while looking at the excellent summary of the factors contributing to the decline of private sector pension provision. Leaving aside the more general points about costs and risks, and those thought applicable to the (mainly) unfunded public service schemes which have been largely addressed by the planned reforms, I noticed two of the factors thought specific to funded defined benefits (DB) plans:
- A more onerous burden on trustees of plans, including member representation, and knowledge and understanding; and
- Company pension accounting rules requiring liabilities to be measured based on corporate bond yields.
As the GAD paper makes clear, the Public Service Pensions Act will result in a significant increase in interventions on governance in particular in some public sector schemes. The Pensions Regulator’s recent consultation on regulating public service pension schemes is also proposing a 60 page code of practice be adopted in respect of the governance and administration of these schemes. This looks like the “onerous burden” which has been visited on the private sector over the last 20 years all over again.
The other point is not directly comparable, as company pension accounting rules do not apply to the public sector. However, as pointed out by the Office for National Statistics (ONS) this week, supplementary tables to the National Accounts calculating public sector pensions liabilities will be required of all EU member states from September this year onwards, to comply with the European System of Accounts (ESA) 2010. These are carried out using best estimate assumptions (ie without margins for prudence) and a discount rate based on a long term estimate of GDP growth (as compared to the AA corporate bond yield required by accounting rules).
The ONS released the first such tables published by any EU member state, for 2010, in March 2012. This for the first time values the liabilities in respect of unfunded public sector pension entitlements, at £852 billion, down from £915 billion at the start of the year.
I think there is a real possibility that publication of this information, as it has for DB pension schemes, will result in pressure to reduce these liabilities where possible. An example would be one I mentioned in a previous post, where mass transfers to defined contribution (DC) arrangements from public sector schemes following the 2014 Budget have effectively been ruled out because of their potential impact on public finances. If such transfers reduced the liability figure under ESA 2010 (which they almost certainly would) the Government attitude to such transfers might be different in the future.
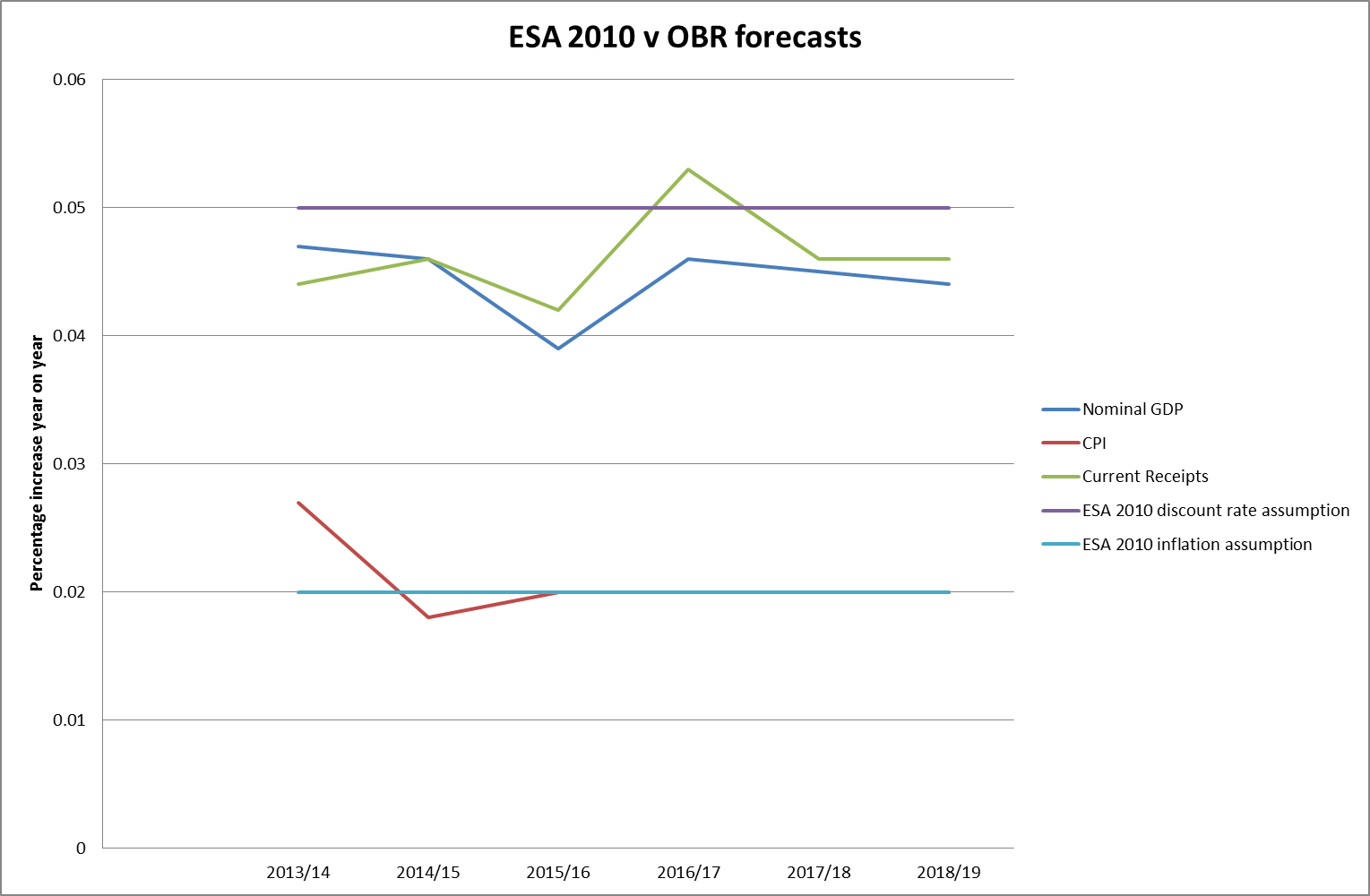
The second point concerned the ESA 2010 assumptions themselves. There was a previous consultation on the best discount rate used for these valuations, ie the percentage by which a payment required in one year’s time is more affordable than one required now, with GDP growth coming out as the preferred option. Leaving aside the many criticisms of GDP as an economic measure, one option which was not considered apparently was the growth in current Government receipts, although this would seem in many ways to be a better guide to the element of economic growth relevant to the affordability of public sector provision. Taking the Office for Budget Responsibility (OBR) forecasts from 2013-14 to 2018-19 with the fixed ESA 2010 assumptions for discount rate and inflation of 5% pa and 2% pa respectively gives us an interesting comparison.
 The CPI assumption appears to be fairly much in line with forecasts, but the average nominal GDP and current receipt year on year increase over the next 6 years of forecasts are 4.47% pa and 4.61% pa (4.72% pa if National Accounts taxes are used rather than all current receipts) respectively. A 0.5% reduction in the discount rate to 4.5% pa would be expected to increase the liability by over 10%.
The CPI assumption appears to be fairly much in line with forecasts, but the average nominal GDP and current receipt year on year increase over the next 6 years of forecasts are 4.47% pa and 4.61% pa (4.72% pa if National Accounts taxes are used rather than all current receipts) respectively. A 0.5% reduction in the discount rate to 4.5% pa would be expected to increase the liability by over 10%.
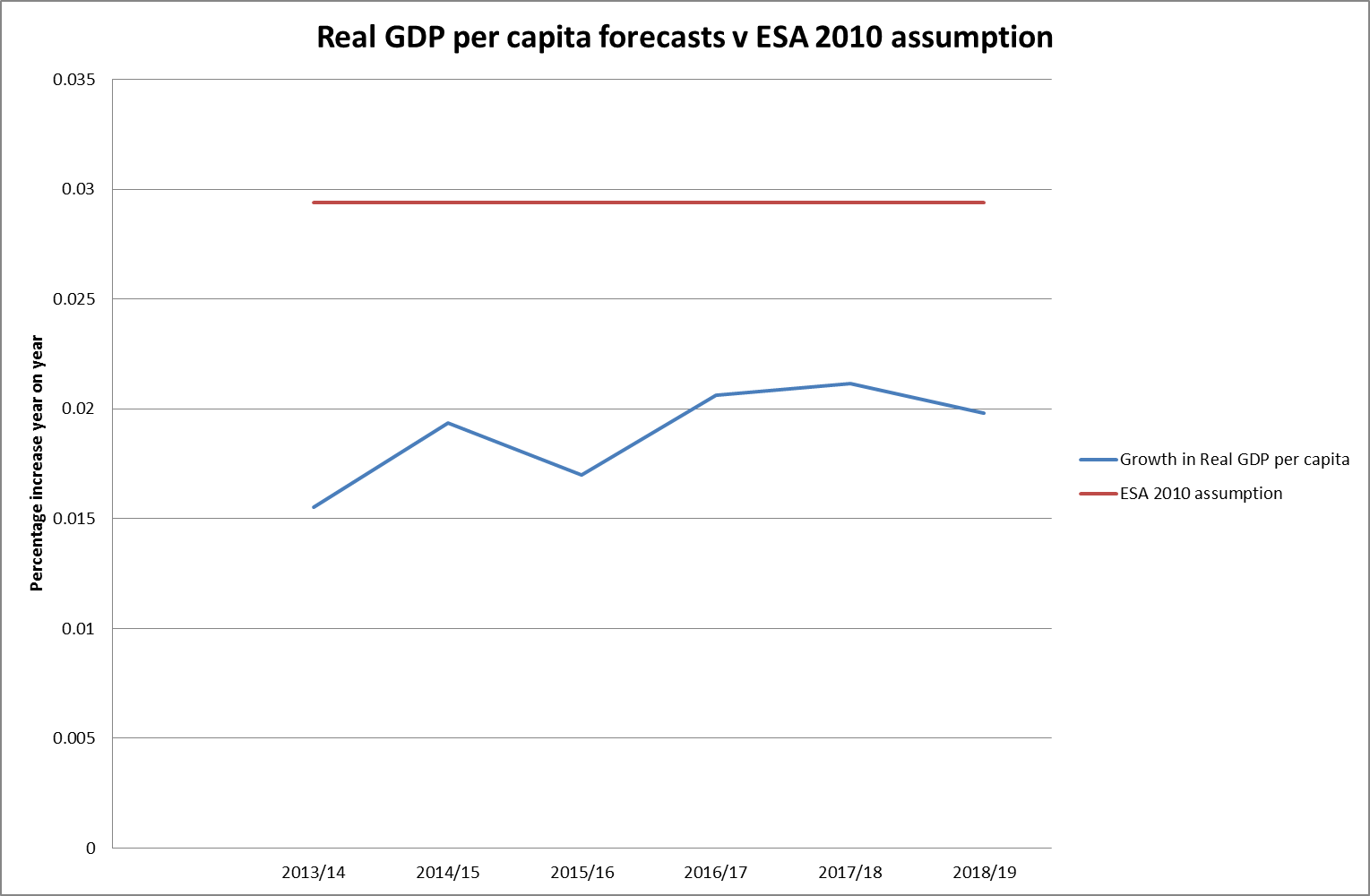
Another, possibly purer, measure of economic growth, removing as it does the distortions caused by net migration, would be the growth of GDP per capita. If we take the OBR forecasts for real GDP growth per capita and set it against the long term ESA 2010 assumption of 1.05/1.02 – 1 = 2.94% the comparison is even more interesting:
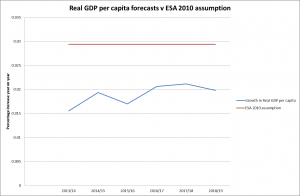 In this case the ESA assumption is around 1% pa greater than the forecasts would suggest, making the liability less than 80% of where it would be using the average forecast value.
In this case the ESA assumption is around 1% pa greater than the forecasts would suggest, making the liability less than 80% of where it would be using the average forecast value.
The ESA 2010 assumptions are intended to be fixed so that figures for different years can easily be compared. It would clearly be easy to argue for tougher assumptions from the OBR forecasts (although the accuracy of these has of course not got a great track record), but perhaps more difficult to find an argument for relaxing them further.
Whether the consensus holds over keeping them fixed when and if the liability figures start to get more prominence and a lower liability becomes an important economic target for some of the larger EU member states remains to be seen. However if the assumptions cannot be changed, since public sector benefits now have a 25 year guarantee in the UK (other than the normal pension age now equal to the state pension age being subject to review every 5 years), then the cost cap mechanism (ie higher member contributions) becomes the only available safety valve. So we can perhaps expect nurses’ and teachers’ pension contributions to become the battleground when public sector pension affordability becomes a hot political issue once more.
We can poke fun at the Government’s enthusiasm to take on the Royal Mail Pension Plan and its focus on annual cashflows which made it look beneficial for their finances over the short term, but we may also look back wistfully to the days before public sector pensions stopped being viewed as a necessary expense of delivering services and became instead a liability to be minimised.