There are many papers about model risk, and the dangers of blindly relying on algorithms or metrics without allowing for human judgement at any point in any subsequent analysis (in effect “baking in” whatever analysis was done at the time the computer model or algorithm was constructed as the final word), but these can often descend into the same level of technical impenetrability as the programmes they are attempting to critique.
I watched the film Sully: Miracle on the Hudson for the first time this week, on the anniversary of the landing on the Hudson. In the final scenes there is a hearing (spoiler alert!), where the evidence presented up until that point based on computer simulations, with and without pilots involved, was leading to the unanimous conclusion that Sully and Skiles could have turned back to La Guardia or Teterboro airports rather than landing on the Hudson River in January. However Sully had appealed to have the video recordings of the pilot simulations shown to the hearing, and these revealed the pilots responding to the catastrophic bird strikes which had taken out both engines (again something later confirmed when the actual engines were recovered, but which the simulations themselves did not accept because of the instrument readings on one of the engines from the aircraft) by calmly immediately setting course for La Guardia or Teterboro with no decision or response or recovery time needed at all. When a 35 second allowance for this was inserted into the simulations, the results were fatal crashes in both cases.
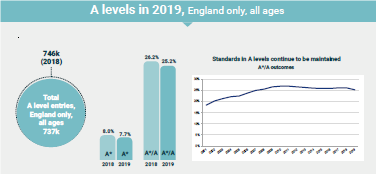
What struck me was how invisible this deficiency in the programming of the simulation would have been without a cockpit recording of the simulations. In many of the programmes we use to automate judgement-heavy processes, such as recruitment, many of the capital allocation decisions in financial institutions or even A-level grades, we do not have anything equivalent to a cockpit recording available to us. Perhaps we wait until either events prove us wrong (bad) or those on the receiving end of our automated decisions start to complain in sufficient numbers for us to reconsider (worse). What if quite a large proportion of the cost savings from automating these processes is in fact illusory as a result of our not putting enough time and attention into the original programming and/or not setting aside enough budget for maintaining it and challenging its decisions with parallel processes which do allow for human judgement? How much bigger is this problem going to become in the era of machine learning, where the programmes we are running are themselves several steps of abstraction away from those originally written by humans?
Our ability to programme machines to carry out billions of calculations in seconds would have been regarded as miraculous only a few decades ago and is still pretty astonishing to us now. We need to start thinking a lot more about how we can live alongside these ever more capable machines amicably over the long term. And it can’t be only programmers who get to see what the machines are doing – whatever the technical problems of allowing the equivalent of a cockpit recording to be made which can be understood by any of us, they need to be solved with as much urgency as the process automation itself. All of our decision-making processes need to be understandable and challengeable by the society in whose name they are carried out. It’s time to get serious now about our miracles.